![]()
![]()
![]()
Le Langage C++cours n° 1 |
Patrick TRAU 06/10/04
Je suppose que vous savez utiliser un ordinateur, et comprenez comment il fonctionne. Voir cours d'IUP1 (http://www-ipst.u-strasbg.fr/internet/techinfo/).
Un ordinateur est une machine bête, ne sachant qu'obéir, et à très peu de choses :
Sa puissance vient du fait qu'il peut être programmé, c'est à dire que l'on peut lui donner, à l'avance, la séquence (la suite ordonnée) des ordres à effectuer l'un après l'autre. Ces ordres, codés en binaire, sont sauvés dans un fichier nommé « exécutable » (.exe sous Windows). Le grand avantage de l'ordinateur est sa rapidité. Par contre, c'est le programmeur qui doit TOUT faire.
L'ordinateur ne comprenant que des ordres codés en binaire (le langage machine) peu pratiques d'emploi, des langages dits "évolués" ont été mis au point pour faciliter la programmation, au début des années 60, en particulier FORTRAN (FORmula TRANslator) pour le calcul scientifique et COBOL pour les applications de gestion. Puis, pour des besoins pédagogiques principalement, ont été créés le BASIC, pour une approche simple de la programmation, et PASCAL au début des années 70. Ce dernier (comme le C) favorise une approche méthodique et disciplinée (on dit "structurée").
Le C a été développé conjointement au système d'exploitation UNIX, dans les Laboratoires BELL, par Brian W Kernigham et Dennis M Ritchie, qui ont défini en au cours des années 70, dans "The C Language", les règles de base de ce langage. Le but principal était de combiner une approche structurée (et donc une programmation facile) avec des possibilités proches de celles de l'assembleur (donc une efficacité maximale en exécution, quitte à passer plus de temps de programmation), tout en restant standard (c'est à dire pouvoir être implanté sur n'importe quelle machine). Puis ce langage a été normalisé (norme ANSI), cette norme apportant un nombre non négligeable de modifications au langage. Contrairement au Pascal, ce langage est principalement destiné aux programmeurs confirmés, il sera donc avare en commentaires et vérifications, supposant que le programmeur sait ce qu'il fait.
A la fin des années 80, Bjarne Stroustrup crée le C++, qui garde toutes les possibilités du C, l'améliorant (commentaires, constantes, passage d'arguments par adresse, arguments par défaut...) mais surtout en y ajoutant les objets (encapsulation, héritage, polymorphisme, surcharge...). Le C++ combine donc toutes les possibilités de la programmation «classique» et la puissance de l'approche «objets». Je préciserai quelles fonctionnalités sont spécifiques au C++ (les autres fonctionnant également en C ANSI)
Le C++ est un langage compilé, c'est à dire qu'il faut :
Pour aller plus en détails (voir schéma) : Pour commencer, la compilation d'un source C++ se fait en plusieurs phases. La première (la précompilation) permet des modifications du code source, et ce à l'aide de « directives » (commençant par #). Ce n'est que dans une seconde phase que ce source intermédiaire est effectivement traduit en langage machine : l'objet.
Un programme exécutable peut être fabriqué à partir de divers éléments. On peut par exemple décomposer son programme source C++ en plusieurs fichiers, que l'on compile séparément. Cela permet, en cas de modification d'un seul source, de ne recompiler que celui-ci (et réutiliser les autres objets tels quels). Cela permet également d'utiliser un même objet dans différents programmes (s'ils nécessitent une fonction commune). On peut également utiliser des objets générés à partir d'un autre langage (si, quand on les a écrits, on utilisait un autre langage, ou si quelqu'un nous a donné ses sources).
Tout ces objets doivent être regroupés en un seul programme exécutable : c'est le « link ». Il permet également de lier diverses librairies. Les librairies sont des objets qu'on nous a fournies toutes faites : fonctions d'accès aux ressources de l'ordinateur, fonctions graphiques, bibliothèques de fonctions mathématiques... A la différence d'un objet, seules les parties utiles d'une librairie seront chargées dans l'exécutable.
Pour qu'un programme puisse être exécuté, il faut qu'il soit complètement chargé dans la mémoire de l'ordinateur. C'est pourquoi tous les objets et librairies statiques sont incorporés dans l'exécutable (qui pourra donc devenir assez gros). Dans les systèmes d'exploitation multitâches, si plusieurs programmes utilisent une même librairie, elle serait alors copiée plusieurs fois en mémoire. C'est pourquoi on utilise des librairies dynamiques (.dll sous Windows) : l'exécutable sait simplement qu'elle est nécessaire. Si, lors du chargement du programme, elle est déjà présente, inutile de la charger une seconde fois. Certains systèmes ont du mal par contre à décider quand supprimer une librairie dynamique de la mémoire (en particulier si l'un des programmes l'ayant demandé à planté).

Voici un schéma définissant cette structure. Il nous servira tout au long du cours.
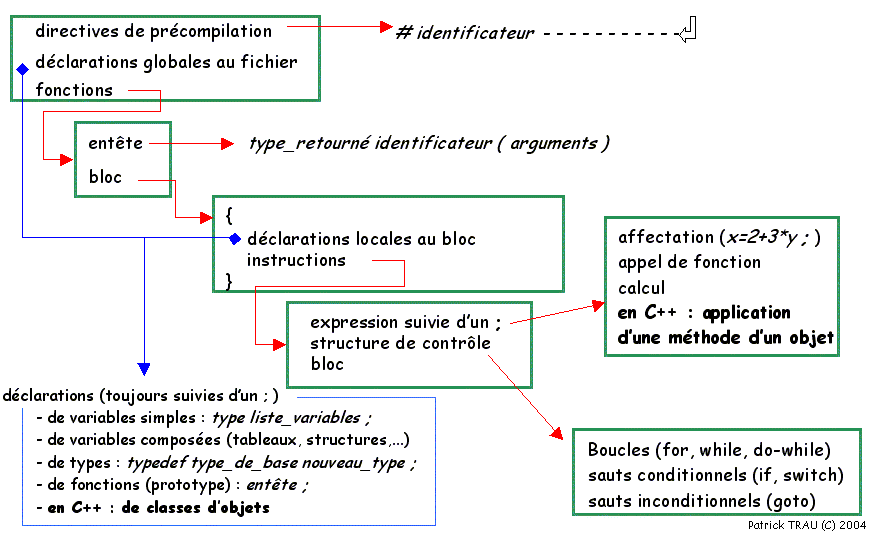
Regardons ce petit programme, et tentons d'en repérer les différentes parties :
1) /* premier exemple de programme C++ */
2) #include <iostream.h>
3) #define TVA 19.6
4) int main(void)
5) {
6) float HT,TTC; //on déclare deux variables
7) cout<<"veuillez entrer le prix HT : ";
8) cin>>HT;
9) TTC=HT*(1+(TVA/100));
A) cout<<"prix TTC : "<<TTC<<"\n";
B) }
Définissons quelques termes importants.
Le commentaire est une partie du fichier source qui n'est pas prise en compte par le compilateur. En C, un commentaire commence par « /* » et finit par « */ » (voir ligne 1). Il peut y avoir tout ce qu'on veut entre (y compris plusieurs lignes), sauf un commentaire du même type (on dit qu'ils ne peuvent pas être imbriqués). En C++ on peut également utiliser le commentaire commençant par « // » et se terminant à la fin de la même ligne. Ce second type de commentaire peut par contre être imbriqué à l'intérieur d'un commentaire /* ... */.
Le séparateur en C/C++ sert à séparer des mots. Il peut être un espace, une tabulation, un retour à la ligne (sauf dans les directives de précompilation), un commentaire, ou une combinaison de plusieurs d'entre eux. Vous pouvez donc aller à la ligne à tout endroit où l'on peut mettre un espace, ou à l'inverse regrouper sur une même ligne plusieurs instructions séparées par un espace.
Un identificateur est un nom que le programmeur donne à une entité. Un identificateur est composé de lettres (majuscules ou minuscules non accentuées, une majuscule étant considérée comme différente de sa minuscule, donc de A à Z et de a à z), de chiffres (0 à 9) et du signe « souligné » (underscore). Commencez le toujours par une lettre (et utilisez généralement des minuscules). Un identificateur est terminé soit par un séparateur, soit parce qu'il est suivi d'un caractère interdit (ni lettre ni chiffre ni souligné). Dans ce dernier cas, vous avez néanmoins le droit d'insérer un séparateur entre l'indentificateur et ce caractère. Par exemple, dans la ligne 4 il FAUT mettre au moins un espace entre int et main (sinon cela forme un seul identificateur), on peut (mais n'est pas obligé) insérer un séparateur devant et derrière les parenthèses. Il est par contre impossible d'insérer un séparateur au milieu d'un identificateur.
La première chose que fait le compilateur, c'est d'appliquer les directives de précompilation. Elles commencent toujours par #, et se finissant à la fin de la ligne (il n'y en a donc qu'une par ligne). Elles sont appliquées lors de la précompilation, indépendamment des règles du C++ (ce n'est que le résultat qui doit obligatoirement respecter les règles du compilateur). Une directive s'applique depuis l'endroit où elle est écrite jusqu'à la fin du fichier (c'est pourquoi on les place souvent au début du fichier).
#define identificateur texte de remplacement :
à chaque fois que le précompilateur rencontrera (dans
la suite du fichier) l'identificateur, il le remplacera par le texte
de remplacement. Dans notre exemple (ligne 3), il remplacera le mot
TVA par 19.6 partout. Ces transformations sont faites lors de la
précompilation, où l'on ne fait que du "traitement
de texte", c'est à dire des remplacements d'un texte par
un autre sans chercher à en comprendre la signification.
Attention, le premier espace (après define) définit le
début de l'identificateur (sans espace); le second définit
le début du texte de remplacement (qui se finit à la
fin de la ligne donc on peut y mettre des espaces). On peut par
exemple se servir de cela pour définir un nouveau langage
francisé :
#define si if
#define sinon else
#define tant_que while
etc...
On peut également définir des macros :
Si l'on définit : #define carre(a) a*aalors
carre(x) sera transformé en
x*x (ça convient bien),
mais 1+carre(x+1) en 1+x+1*x+1
(qui vaudra 1+x+(1*x)+1).
Alors qu'avec : #define carre(a) ((a)*(a))
sera transformé en
carre(x)((x)*(x))
(convient encore) et 1+carre(x+1)
en 1+((x+1)*(x+1)) (ce qui est
bien ce que l'on attendait).
#include "nomdefichier" : inclure un fichier
à la place de cette ligne. Ce fichier est défini par
le programmeur, il est cherché dans le même répertoire
que le fichier source. Vous pourriez par exemple mettre tous les
#define nécessaires pour franciser le langage dans le
fichier « monlangage.inc » et l'inclure dans
tous vos programmes par #include
"monlangage.inc"
#include <nomdefichier> : inclut un fichier système (fourni par le compilateur ou le système d'exploitation). Vous n'avez pas à vous occuper dans quel répertoire il le cherche. On utilise ces fichiers inclus principalement pour définir le contenu des bibliothèques, avec l'extension .h (header). Dans notre exemple (ligne 2) c'est iostream.h, fichier définissant les flux standard d'entrées/sorties (en anglais Input/Output stream), qui feront le lien entre le programme et la console (clavier : cin / écran : cout).
Dans notre petit exemple, nous en arrivons enfin à notre programme. Rappelez-vous que l'on cherche à situer chaque ligne de l'exemple dans le schéma. Nous trouvons :
type listevariables;
Une variable est un case mémoire de l'ordinateur, que l'on se réserve pour notre programme. On définit le nom que l'on choisit pour chaque variable, ainsi que son type, ici float, c'est à dire réel (type dit à virgule flottante, d'où ce nom). Nous avons donc dans cet exemple deux variables de type « float », nommée HT et TTC. Les trois types scalaires de base du C sont l'entier (int), le réel (float) et le caractère (char). On ne peut jamais utiliser de variable sans l'avoir déclarée auparavant. Une faute de frappe devrait donc être facilement détectée, à condition d'avoir choisi des noms de variables suffisamment différents (et de plus d'une lettre).
Détaillons les instructions de notre programme :
cout<<"un texte";
affiche à l'écran le texte qu'on lui donne (entre
guillemets, comme toute constante texte en C++).
cin>>HT; attend que l'on entre une valeur
au clavier, puis la met dans la mémoire (on préfère
dire variable) HT.
une affectation est définie par le signe =. Une affectation se fait toujours dans le même sens : on détermine (évalue) tout d'abord la valeur à droite du signe =, en faisant tous les calculs nécessaires, puis elle est transférée dans la mémoire dont le nom est indiqué à gauche du =. On peut donc placer une expression complexe à droite du =, mais à sa gauche seul un nom de variable est possible, aucune opération. En ligne 9 on commence par diviser TVA par 100 (à cause des parenthèses) puis on y ajoute 1 puis on le multiplie par le contenu de la variable HT. Le résultat de ce calcul est stocké (affecté) dans la variable cible TTC.
la ligne A affichera enfin le résultat stocké dans TTC (précédé du texte entre guillemets, et suivi d'un retour à la ligne noté « \n ».